.png)
Key Takeaways
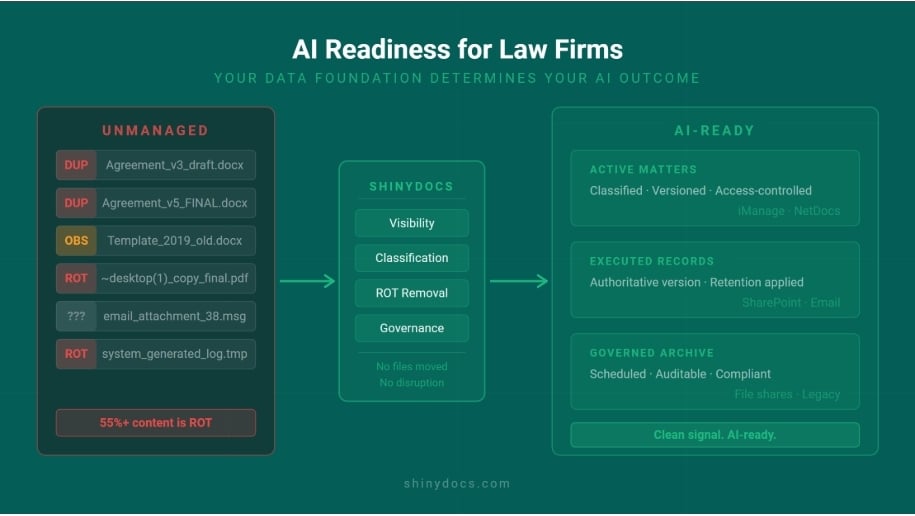
- Automated data remediation finds, classifies, and defensibly deletes redundant, obsolete, and trivial (ROT) files across every connected system.
- File cleanup cuts storage costs, reduces compliance risk, and prepares data for AI without migrating any files.
- Poor data quality costs organizations $12.9 million annually, according to Gartner, making cleanup a measurable financial priority.
- Data breaches involving dark data cost 16.2 percent more and take over 26 percent longer to identify, per IBM.
- Shinydocs classifies and governs content across file shares, cloud repositories, and legacy systems without migrating files first.
.svg)






