AI doesn’t fix a data problem. It amplifies it. Before you implement anything, you need a clear plan for preparing your legal data for AI.
(Aprox. 6 mins read)
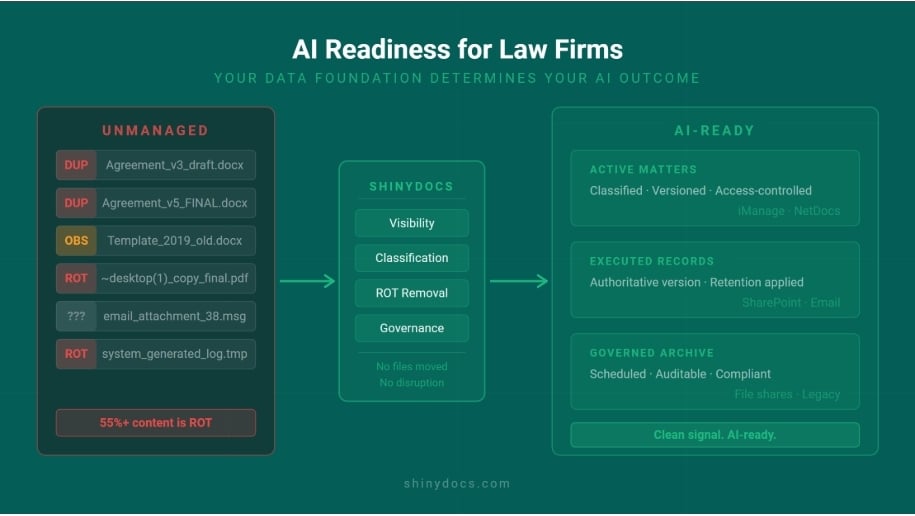
AI doesn’t fix a data problem. It amplifies it. Before you implement anything, you need a clear plan for preparing your legal data for AI.
(Aprox. 6 mins read)

(Approx. 5 mins read)

(Approx. 4 mins read)

Data migration is a pivotal process for organizations looking to upgrade systems, consolidate data, or move to the cloud. Understanding the various types of data migration is crucial for ensuring a smooth and efficient transition. This comprehensive guide explores the different types of data migration, their benefits, challenges, and best practices.
Data migration refers to the process of transferring data between storage types, formats, or computer systems. This process is essential for organizations implementing new systems, upgrading existing ones, or consolidating data to improve efficiency, reduce costs, or enhance system performance. Data migration encompasses several critical stages to ensure the successful transfer and integrity of data.
Storage migration involves moving data from one storage medium to another. This is typically done to upgrade to faster, more efficient storage systems or to consolidate storage resources. The main benefits include improved performance, reduced costs, and enhanced data management capabilities.
Database migration involves transferring data between databases or from an older database version to a newer one. This is common when upgrading database software or moving to a different database platform. Key considerations include ensuring data integrity, maintaining data relationships, and minimizing downtime.
Application migration entails moving application software from one environment to another. This could be from on-premises to the cloud, or between cloud environments. It’s often driven by leveraging new technologies, improving scalability, or reducing operational costs.
Cloud migration refers to the process of moving data, applications, and other business elements to a cloud computing environment. This type of migration is popular for its scalability, flexibility, and cost-efficiency. Cloud migration strategies include rehosting, refactoring, and re-platforming.
Business process migration involves moving applications and associated data to a new environment that supports the organization’s business processes. This is often part of a larger business transformation initiative and can include migrating business functions like HR, finance, and operations.
Data center migration involves moving data and applications from one data center to another. This could be due to consolidation, relocation, or transitioning to a cloud-based data center. Key considerations include minimizing downtime, ensuring data integrity, and maintaining service levels.
A successful data migration starts with detailed planning. Define your objectives, assess the scope, and develop a comprehensive strategy that includes timelines, resources, and potential risks.
Before migration, conduct a thorough audit of your data. Identify redundant, obsolete, or trivial (ROT) data that can be cleaned up to streamline the migration process.
Data quality is paramount during migration. Implement data validation and cleansing processes to ensure the data being migrated is accurate, complete, and consistent.
Testing is critical to a successful data migration. Conduct multiple rounds of testing to identify and address any issues before the actual migration. This includes testing the migration process, data integrity, and system performance.
During the migration, continuously monitor the process to ensure it is proceeding as planned. After migration, validate that all data has been successfully transferred and that applications are functioning correctly in the new environment.
Understanding the various types of data migration and following best practices is essential for a smooth transition. Whether migrating storage, databases, applications, or entire data centers, careful planning, thorough testing, and ongoing monitoring are key to mitigating risks and ensuring success. By leveraging the right strategies and tools, organizations can achieve their migration goals while minimizing disruptions and maximizing benefits.
Shinydocs automates the process of finding, identifying, and actioning the exponentially growing amount of unstructured data, content, and files stored across your business.
Our solutions and experienced team work together to give organizations an enhanced understanding of their content to drive key business decisions, reduce the risk of unmanaged sensitive information, and improve the efficiency of business processes.
We believe that there’s a better, more intuitive way for businesses to manage their data. Request a meeting today to improve your data management, compliance, and governance.

As organizations grow and evolve, managing data becomes increasingly complex. Two critical processes in data management are data conversion and data migration. Although these terms are often used interchangeably, they refer to distinct processes with unique objectives and methodologies. Understanding the key differences between data conversion and data migration is essential for ensuring data integrity and optimizing system performance. This blog will delve into the nuances of data conversion vs data migration, exploring their definitions, processes, and applications.
Data conversion involves transforming data from one format or structure to another. This process is necessary when systems or applications need to interpret and utilize data differently due to varying data formats, coding standards, or database structures. The primary goal of data conversion is to ensure that data remains usable and accessible after the transformation.
Data migration involves moving data from one system, storage type, or application to another. This process can include data conversion but primarily focuses on transferring data to improve system performance, reduce costs, or upgrade to more advanced technologies. Data migration aims to ensure that data is accurately transferred and fully functional in the new environment.
The primary objective of data conversion is to change data formats and structures to ensure compatibility and usability within a new system or application. This process is essential when systems or applications require data in specific formats to function correctly. Data conversion focuses on transforming the data without necessarily moving it to a new system. For example, converting data from a legacy format to a more modern format to be used in a new application while maintaining its original context and meaning.
Data migration, on the other hand, aims to transfer data from one system, storage type, or environment to another. While data conversion may be part of this process, the primary focus is on the accurate and efficient relocation of data. The objective of data migration is broader and more comprehensive, encompassing the entire process of moving data to improve system performance, reduce costs, or upgrade to more advanced technologies. This often involves significant changes to the way data is stored and accessed, ensuring it remains functional in the new environment.
The scope of data conversion is typically limited to transforming data within the same system or during integration between systems. The goal is to make the data accessible and usable in its new format without changing its location. This process might involve converting data fields, adjusting data types, or restructuring datasets to match the requirements of the target system or application. Data conversion ensures that the data can be seamlessly integrated and utilized by different systems or applications that require it in specific formats.
Data migration involves a broader scope, including moving data across different systems, storage types, or environments. This process is more extensive as it includes planning, assessing, and executing the transfer of data while ensuring minimal disruption to business operations. Data migration often involves not just converting data formats but also moving it to entirely different platforms, such as migrating on-premises databases to cloud-based solutions. This comprehensive approach ensures that all data components are transferred accurately and remain fully functional in the new environment.
The process of data conversion involves several specific steps to ensure the data is transformed accurately:
These steps are focused on changing the data format and structure without moving the data to a different system.
Data migration encompasses a more comprehensive set of processes to ensure successful data transfer:
This extensive process ensures that data is accurately transferred and fully functional in the new environment.
Data conversion is generally less complex than data migration. It focuses primarily on format and structure changes within a single system. The key challenges involve ensuring that data is accurately transformed and remains usable in its new format. Data conversion might require less planning and fewer resources compared to data migration, making it a more straightforward process when only format changes are needed.
Data migration is inherently more complex, involving multiple systems or environments. This complexity arises from the need to move large volumes of data accurately while ensuring data integrity, compatibility, and system performance. Data migration requires extensive planning, coordination, and testing to mitigate risks such as data loss, corruption, or system downtime. The involvement of various stakeholders, the need for comprehensive validation, and the potential impact on business operations add layers of complexity to the migration process.
Understanding the differences between data conversion and data migration is crucial for effective data management. Data conversion ensures that data remains usable and accessible by transforming it into compatible formats. In contrast, data migration focuses on transferring data across systems or environments to improve performance, reduce costs, or adopt new technologies. By recognizing the unique objectives, scopes, and processes of these two critical functions, organizations can better plan and execute their data management strategies, ensuring data integrity and optimizing system performance.
Shinydocs automates the process of finding, identifying, and actioning the exponentially growing amount of unstructured data, content, and files stored across your business.
Our solutions and experienced team work together to give organizations an enhanced understanding of their content to drive key business decisions, reduce the risk of unmanaged sensitive information, and improve the efficiency of business processes.
We believe that there’s a better, more intuitive way for businesses to manage their data. Request a meeting today to improve your data management, compliance, and governance.

As organizations strive to harness the power of their data, two terms frequently emerge: data discovery and business intelligence (BI). Both play critical roles in data management and decision-making processes, yet they serve distinct purposes and utilize different methodologies. This blog will explore the differences between data discovery and business intelligence, their individual benefits, and how they complement each other to drive business success.
Data discovery is the process of identifying patterns and insights from large sets of data. It involves using visual tools and exploratory techniques to analyze data, uncovering hidden trends, relationships, and anomalies. Data discovery empowers users to delve into their data without needing deep technical expertise, facilitating a more intuitive and interactive approach to data analysis.
Business intelligence (BI) refers to the technologies, applications, and practices for collecting, integrating, analyzing, and presenting business information. The primary goal of BI is to support better business decision-making. BI systems traditionally rely on structured data from databases and data warehouses, providing historical, current, and predictive views of business operations.
While data discovery and business intelligence serve different purposes, they are not mutually exclusive. In fact, they complement each other, providing a comprehensive approach to data management and analysis.
Understanding the differences between data discovery and business intelligence is crucial for leveraging their strengths to drive business success. Data discovery focuses on exploring data to uncover hidden insights, while business intelligence provides structured, in-depth analysis for informed decision-making. By integrating both approaches, organizations can enhance their data analysis capabilities, leading to more comprehensive insights and better strategic decisions.
Shinydocs automates the process of finding, identifying, and actioning the exponentially growing amount of unstructured data, content, and files stored across your business.
Our solutions and experienced team work together to give organizations an enhanced understanding of their content to drive key business decisions, reduce the risk of unmanaged sensitive information, and improve the efficiency of business processes.
We believe that there’s a better, more intuitive way for businesses to manage their data. Request a meeting today to improve your data management, compliance, and governance.
Effective data management is crucial for enterprises looking to gain insights and drive decision-making. Two important concepts that often come up in this context are data discovery and data cataloging. While both play pivotal roles in data management, they serve different purposes and are used in distinct ways. This blog will explore the differences between data discovery and data cataloging, their unique benefits, and how they complement each other in a comprehensive data strategy.
Data discovery is the process of identifying patterns, correlations, and insights within datasets. It involves exploring and analyzing data to uncover hidden trends and relationships that can inform business decisions. Data discovery is often facilitated by interactive tools and visualizations, allowing users to drill down into data and perform ad-hoc analyses.
A data catalog is a comprehensive inventory of data assets within an organization. It provides metadata about data sets, including their source, usage, and lineage, making it easier for users to find and understand the data available to them. Data catalogs often include features like search functionality, data lineage tracking, and user annotations to facilitate data governance and collaboration.
Exploratory Focus: The primary goal of data discovery is to explore and analyze data to uncover hidden patterns, trends, and insights. This process is inherently investigative and allows users to interact with data in a dynamic way. The focus is on finding relationships and anomalies that might not be apparent in pre-defined reports or traditional analysis methods.
User-Driven Analysis: Data discovery emphasizes a user-driven approach where business users, analysts, and non-technical staff can independently explore and analyze data. This autonomy reduces the dependency on IT and allows users to derive insights quickly, responding to business needs in real-time.
Organizational Focus: The main objective of a data catalog is to organize and inventory all data assets within an organization. It aims to create a comprehensive and easily searchable repository that provides users with a clear understanding of what data is available and how it can be used.
Metadata Management: Data catalogs focus on managing metadata—the data about data. This includes details such as data source, creation date, usage, and lineage. Effective metadata management improves data governance and ensures that data assets are properly documented and understood.
Interactive and Visual: Data discovery relies heavily on interactive and visual tools for analysis. These tools, such as dashboards, charts, and graphs, allow users to visualize data trends and patterns easily. The visual nature of these tools makes data more accessible and comprehensible to non-technical users.
Ad-Hoc Analysis: Supports the ability to perform ad-hoc queries and analyses, enabling users to ask spontaneous questions and explore data in real-time. This approach is crucial for addressing immediate business questions and hypotheses without waiting for formal reports to be generated.
Systematic and Structured: Data cataloging involves a systematic and structured approach to collecting and organizing metadata. This ensures consistency and reliability in how data assets are documented and managed.
Search and Retrieval: Provides robust search functionality to quickly locate data assets. This search capability is essential for users to efficiently find the data they need for their analyses and decision-making processes.
Structured and Unstructured Data: Data discovery tools are designed to handle a variety of data types, including structured data from databases and unstructured data such as text, images, and social media content. This versatility enables a more holistic analysis of different data sources.
Pattern Recognition: Employs sophisticated algorithms to identify patterns and trends within diverse datasets. This capability is crucial for uncovering insights that can drive strategic decisions.
Primarily Structured Data: Focuses on cataloging structured data assets, though it can also include metadata about unstructured data. The primary aim is to provide a clear and comprehensive inventory of an organization’s structured data resources.
Metadata Focus: Centers around managing metadata, providing detailed information about data sources, usage, and transformations. This focus helps users understand the data’s lineage and governance aspects.
Business Users and Analysts: Designed for use by business users, data analysts, and non-technical staff. The intuitive and user-friendly tools enable these users to explore and analyze data independently, without needing deep technical knowledge.
Empowerment and Independence: Encourages users to conduct their own data explorations and analyses, fostering a culture of self-service analytics. This independence accelerates the pace of insights and reduces the burden on IT resources.
Data Stewards and IT Professionals: Typically used by data stewards, IT professionals, and data governance teams to manage and oversee data assets. These users are responsible for maintaining data quality, security, and compliance.
Collaboration and Governance: Facilitates collaboration among various stakeholders and ensures robust data governance through organized metadata and comprehensive documentation.
While data discovery and data cataloging serve different purposes, they are complementary processes that together enhance an organization’s data management capabilities.
Understanding the differences between data discovery and data cataloging is crucial for effective data management. Data discovery focuses on exploring data to uncover hidden insights, while data cataloging organizes and inventories data assets to improve accessibility and governance. By integrating both approaches, enterprises can enhance their data strategy, driving better insights, compliance, and decision-making.
Shinydocs automates the process of finding, identifying, and actioning the exponentially growing amount of unstructured data, content, and files stored across your business.
Our solutions and experienced team work together to give organizations an enhanced understanding of their content to drive key business decisions, reduce the risk of unmanaged sensitive information, and improve the efficiency of business processes.
We believe that there’s a better, more intuitive way for businesses to manage their data. Request a meeting today to improve your data management, compliance, and governance.

Managing data effectively is crucial for operational success and strategic decision-making. Two key concepts that often come into play are data migration and data integration. While these terms might seem similar, they refer to distinct processes with unique objectives and methodologies. Understanding the key differences between data migration vs data integration is essential for implementing the right data management strategy. This blog will explore the differences, benefits, and use cases of both data migration and data integration.
Data migration is the process of transferring data from one system, storage type, or application to another. This process is often necessary when organizations upgrade systems, consolidate data centers, or move to cloud-based solutions. The primary goal of data migration is to ensure that data is accurately and securely transferred to a new environment, often involving data transformation to meet the requirements of the target system.
Data integration is the process of combining data from different sources to provide a unified view. This process is essential for creating comprehensive datasets that can be used for analysis, reporting, and decision-making. Data integration involves continuous data flows and synchronization between systems, ensuring that data from various sources is combined and made accessible in real-time or near-real-time.
Understanding the differences between data migration and data integration is crucial for selecting the appropriate strategy for your organization’s data management needs. Here’s an in-depth look at their key differences:
Data migration focuses on moving data from one system to another. This is usually a one-time event triggered by system upgrades, consolidations, or relocations. The primary aim is to ensure data is accurately and securely transferred, often transforming it to meet the new system’s requirements. For example, migrating customer data from an on-premises CRM system to a cloud-based CRM solution to leverage new features and improved performance.
In contrast, data integration combines data from multiple sources to create a unified view. This ongoing process ensures continuous data flow and synchronization between different systems, enabling real-time or near-real-time access to integrated data. For instance, integrating sales data from various regional databases into a centralized data warehouse provides a comprehensive view of global sales performance.
Data migration is project-based, with a clear start and end. It involves significant data transformation and mapping to ensure compatibility with the target system, followed by extensive validation and testing to maintain data integrity post-migration. For example, during a migration project, data from legacy systems is cleaned, transformed, and loaded into a new ERP system, followed by rigorous testing to ensure accuracy.
Data integration is an ongoing process that involves extracting data from various sources, transforming it into a consistent format, and loading it into a target system like a data warehouse. This approach often uses ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) processes to ensure that integrated data is available in real-time for analytics and reporting. For example, a business may continuously integrate customer interaction data from CRM, social media, and e-commerce platforms to gain holistic insights into customer behavior.
Data migration can involve both homogeneous (same type) and heterogeneous (different types) data systems. The focus is on transforming data to meet the specific needs of the new system, ensuring compatibility and usability in the new environment. For instance, migrating structured customer data from an SQL database to a NoSQL database requires significant transformation to align with the new database structure.
Data integration handles diverse data sources, including structured databases, applications, and unstructured sources like text and images. The goal is to standardize data formats for easy access and analysis. For example, integrating structured financial data with unstructured social media data helps businesses understand the impact of social sentiment on financial performance.
Data migration projects are typically managed by IT and data teams responsible for system transitions, often overseen by project managers to ensure alignment with business goals and timelines. For instance, during a system upgrade, the IT department handles the technical aspects of the migration, while project managers coordinate between IT and business stakeholders to ensure a smooth transition.
Data integration is used by business analysts, data scientists, and IT professionals. Business analysts and data scientists use integrated data for insights and decision-making, while IT teams ensure the data flows smoothly and meets governance standards. For example, a data scientist may use integrated sales and customer data to build predictive models, while IT ensures data pipelines are secure and compliant.
While data migration and data integration serve different purposes, they often complement each other in a comprehensive data management strategy.
Understanding the differences between data migration vs data integration is crucial for implementing an effective data management strategy. Data migration focuses on transferring data between systems, often as a one-time event, while data integration continuously combines data from multiple sources to provide a unified view. By leveraging both processes, organizations can enhance their data quality, improve decision-making, and streamline operations.
Shinydocs automates the process of finding, identifying, and actioning the exponentially growing amount of unstructured data, content, and files stored across your business.
Our solutions and experienced team work together to give organizations an enhanced understanding of their content to drive key business decisions, reduce the risk of unmanaged sensitive information, and improve the efficiency of business processes.
We believe that there’s a better, more intuitive way for businesses to manage their data. Request a meeting today to improve your data management, compliance, and governance.
.svg)
